
Ever wished your computer could understand the words on a picture or a scanned paper? Well, get ready to be amazed, because that magic is totally real and it's all thanks to something super cool called Optical Character Recognition or simply OCR!
Let us think about it, OCR has transformed text extraction from images, eliminating manual retyping, it enables computers to "read" and convert static visual information into editable, searchable text, revolutionizing tasks from digitizing archives to processing invoices, making our lives easier and more efficient!
1- What is OCR?
Okay, so you already know OCR is super cool, right? But have you ever stopped to think about the magic behind it? Imagine you've got a stack of old printed documents, maybe some old school notes, typing all that text out by hand would be, well, a total drag, that's where OCR swoops in like a superhero!
At its core, OCR is all about teaching computers to "read" text from images, just like we do, think of it like this: when you look at a letter "A" on a page, your brain instantly recognizes it, but for a computer, it's just a bunch of pixels, a jumble of dots, OCR acts as the translator, taking that visual information and turning it into something editable and searchable real, live text!
So, how does this all happen? briefly, it starts with an image, that’s all you need! And the OCR software then goes to work, first prepping the image, it might straighten it out, enhance the contrast, and even remove any pesky smudges, next, it looks for distinct regions of text, separating them from the background, this is where the real "reading" begins! The software analyzes each character, breaking it down into features like lines, curves, and angles. It compares these features to a vast library of known characters, and once it makes a match, it converts that image of a character into its digital equivalent.
2- Why is OCR Useful?
Beyond just entering data, OCR makes everything searchable. Instead of flipping through pages, you can instantly find any word or phrase in a digitized document, just like on a website. This is incredibly useful for finding specific info fast.
OCR also boosts accessibility. It can turn printed text into spoken words for people with visual impairments and makes document translation much easier, helping to bridge language gaps.
OCR works its magic in many areas:
Healthcare: Quickly digitizes patient records for better care.
Finance: Speeds up processing checks and loan applications.
Education: Students can turn textbook pages into editable notes.
Legal: Organizes vast amounts of legal documents for easy searching.
Retail: Helps self-checkouts quickly scan items.
Archiving: Preserves historical documents and makes them accessible.
Here is an example from Docuglean.com:
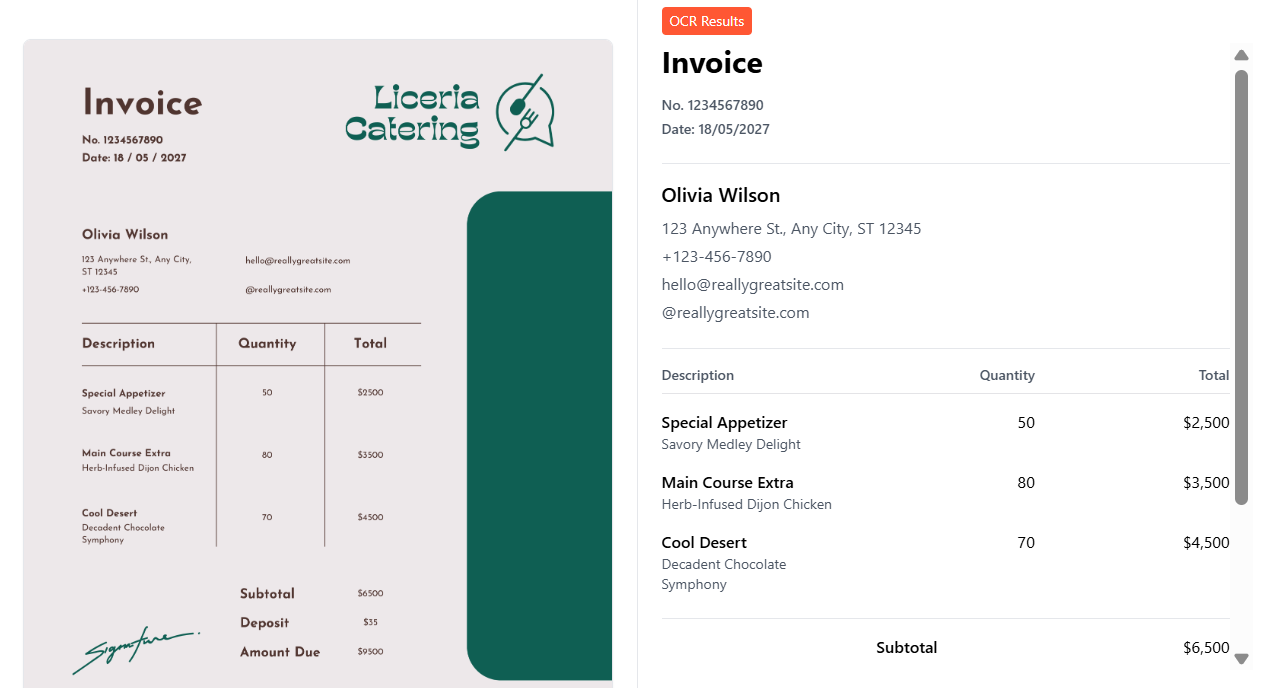
See? It’s magical!
3- How Can You Use OCR Without Any ML Experience?
Yes, you can!
You really can use OCR without any knowledge in machine learning! Amazing isn’t it? Here are some examples that you can use:
Tesseract Open-Source OCR:
Tesseract OCR is a powerful, free, open-source engine for converting images to text, developers use Python wrappers like pytesseract to integrate it, it's easy to use with basic coding, requiring no ML expertise, install Tesseract, then use simple functions to extract text from images, making digitization accessible, you can check it now here.
It is very easy to install using just one line of code:
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]Docling:
Docling simplifies document processing, parsing diverse formats — including advanced PDF understanding — and providing seamless integrations with the gen AI ecosystem, you can check it here
Docling is easy to use and you can get started with it with only a few lines of code:
from docling.document_converter import DocumentConvertersource = "https://arxiv.org/pdf/2408.09869" # document per local path or URLconverter = DocumentConverter()result = converter.convert(source)print(result.document.export_to_markdown()) # output: "## Docling Technical Report[...]"Docuglean AI SDK:
Docuglean is a unified SDK for intelligent document processing using State of the Art AI models. Docuglean provides multilingual and multimodal capabilities with plug-and-play APIs for document OCR, structured data extraction, annotation, classification, summarization, and translation. It also comes with inbuilt tools and supports different types of documents out of the box, check it out here, and learn how to use it here.
Docuglean AI makes it easy for you to use OCR with no ML experience, here is an example code snippet:
import { ocr } from 'docuglean';
const result = await ocr({
filePath: './document.pdf',
provider: 'mistral',
model: 'mistral-ocr-latest'
apiKey: 'your-api-key'
});Enjoyed the article? star us now! 🌟
Got question/feedback/request? Drop them in the comments! 🖊️


