
DeepSeek just dropped their new DeepSeek-R1 model, and honestly, it's a big deal. This isn't just an upgrade from their earlier DeepSeek-R1-Lite-Preview – it shows they're coming for OpenAI's lunch in the reasoning model space.
With OpenAI planning to roll out o3 later this year, the competition in reasoning models is heating up fast. DeepSeek might be playing catch-up in some areas, but its open-source approach and dramatically lower prices make it seriously worth considering.
I've been playing with DeepSeek-R1 since it launched, and I've updated this post to cover not just the tech specs but also the aftermath – including how it shook up the stock market, what it means for AI economics, and OpenAI's accusations that DeepSeek ripped off their models.
What's DeepSeek-R1?
DeepSeek-R1 is an open-source reasoning model from DeepSeek, a Chinese AI company. It's built specifically for logical thinking, math problem-solving, and making decisions in real-time.
What makes reasoning models like DeepSeek-R1 and OpenAI's o1 different from regular language models is that they show their work. You can actually see how they think:

This means you can follow their logic step by step, making it easier to understand (and question) their conclusions. That's huge for researchers or anyone making complex decisions where you need to explain your reasoning.
The real kicker is that DeepSeek-R1 is open-source. Unlike closed models, developers and researchers can dig into it, tweak it, and deploy it (within certain technical limits like computing resources).
How they built it

Let me walk you through DeepSeek-R1's development journey, starting with its predecessor.
DeepSeek-R1-Zero
DeepSeek-R1 started with R1-Zero, which was trained entirely through reinforcement learning. This approach gave it solid reasoning abilities but created major headaches – the outputs were often a mess to read, and the model would randomly mix languages mid-response. Not exactly user-friendly.
The problems with pure reinforcement learning
Going all-in on reinforcement learning resulted in outputs that made logical sense but were structured terribly. Without supervised data to guide it, the model struggled to communicate clearly. Pretty big problem if you actually need to understand the results.
How DeepSeek-R1 fixed these issues
DeepSeek changed course with R1 by blending reinforcement learning with supervised fine-tuning. This hybrid approach used carefully selected datasets to improve readability and coherence. The language mixing and fragmented reasoning mostly disappeared, making the model actually useful in the real world.
If you're into the technical details, check out their release paper. It's a good read.
The Distilled Models
AI distillation is basically creating smaller, more efficient models from bigger ones – preserving most of the reasoning power while cutting down computational demands. DeepSeek used this technique to create several models based on Qwen and Llama architectures.
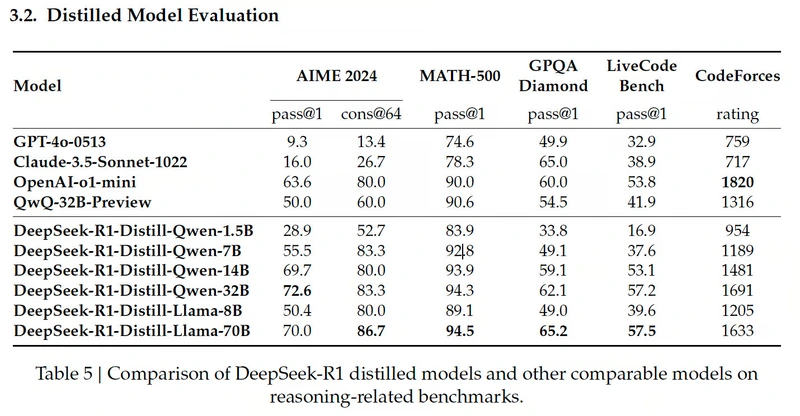
(Image Source: DeepSeek’s release paper)
Qwen-based models
DeepSeek's Qwen-based models focus on efficiency and scalability:
DeepSeek-R1-Distill-Qwen-1.5B The smallest of the bunch, hitting 83.9% on MATH-500 (high-school math problems). Pretty impressive for its size, but it tanks on LiveCodeBench (16.9%), showing it's not cut out for coding tasks.
DeepSeek-R1-Distill-Qwen-7B This one crushes MATH-500 with 92.8% and does decently on GPQA Diamond (49.1%), which tests factual knowledge. Its LiveCodeBench (37.6%) and CodeForces (1189 rating) scores show it's still not great for complex coding.
DeepSeek-R1-Distill-Qwen-14B Strong on MATH-500 (93.9%) and decent on GPQA Diamond (59.1%). It's better at coding than its smaller siblings, with LiveCodeBench at 53.1% and CodeForces at 1481, but still has room to grow.
DeepSeek-R1-Distill-Qwen-32B The big dog of the Qwen models nails AIME 2024 (72.6%), which tests advanced multi-step math reasoning. It also excels on MATH-500 (94.3%) and GPQA Diamond (62.1%). While its coding scores are better (LiveCodeBench 57.2%, CodeForces 1691), it's still not a coding specialist.
Llama-based models
The Llama-based models focus more on raw performance:
DeepSeek-R1-Distill-Llama-8B Good on MATH-500 (89.1%) and okay on GPQA Diamond (49.0%), but lags on coding (LiveCodeBench 39.6%, CodeForces 1205). Not as well-rounded as the Qwen models.
DeepSeek-R1-Distill-Llama-70B The beast of the distilled models. Top performer on MATH-500 (94.5%) and amazing on AIME 2024 (86.7%). Also handles coding pretty well (LiveCodeBench 57.5%, CodeForces 1633) – roughly on par with OpenAI's o1-mini or GPT-4o.
How to get your hands on DeepSeek-R1
You've got two main options for using DeepSeek-R1:
Web access: DeepSeek chat platform
The simplest way to try it out. Just head to their chat page or click "Start Now" on their homepage.

After signing up, select "Deep Think" mode to see DeepSeek-R1's step-by-step reasoning in action.
API access
If you want to build applications with DeepSeek-R1, you'll need their API:
Register on the DeepSeek Platform to get an API key
The API uses the same format as OpenAI's, making it easy to switch if you're already familiar with their tools
Check out their API docs for detailed instructions
Pricing (as of march 18, 2025)
The chat platform is free to use, but you're limited to 50 messages per day in "Deep Think" mode. Good for playing around but not for serious work.
The API offers two models with these prices (per 1M tokens):
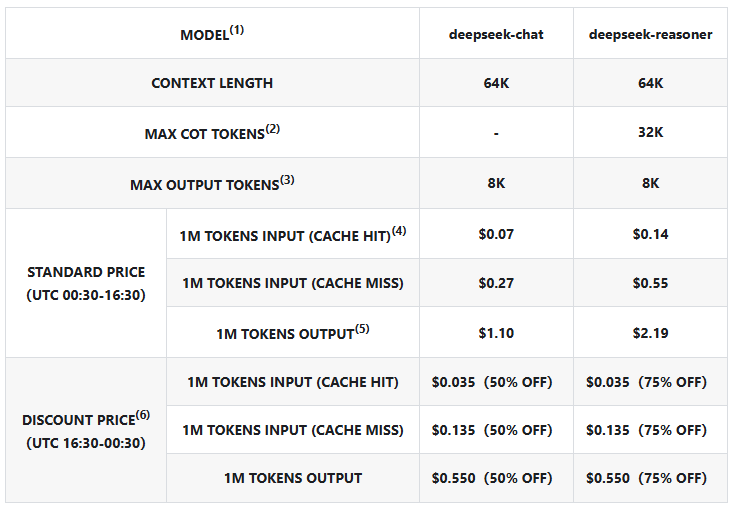
(Image Source: DeepSeek’s pricing page)
For the most current pricing and details on calculating Chain-of-Thought costs, check DeepSeek's pricing page.
DeepSeek-R1 vs. OpenAI O1: How they stack up
DeepSeek-R1 goes head-to-head with OpenAI o1 across several benchmarks, often matching or even beating it:
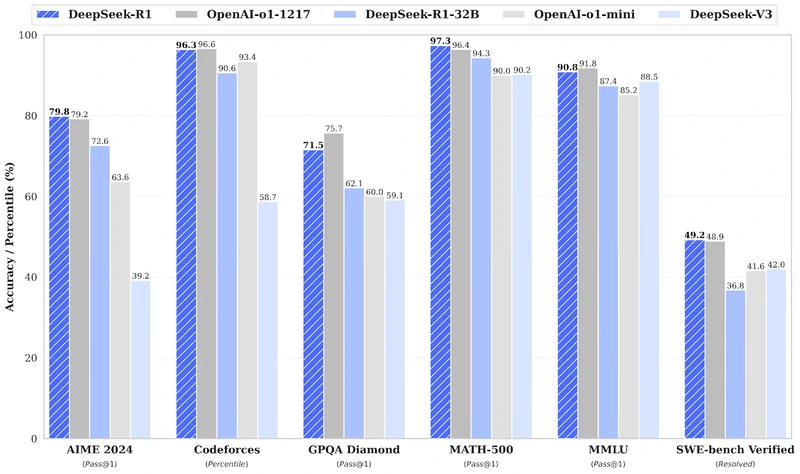
(Image Source: DeepSeek’s release paper)
Math skills
On AIME 2024 (advanced multi-step math reasoning), DeepSeek-R1 scores 79.8%, edging out OpenAI o1-1217's 79.2%.
For MATH-500 (high-school math problems), DeepSeek-R1 leads with 97.3% versus OpenAI o1-1217's 96.4%.
Coding ability
On Codeforces (coding and algorithmic reasoning), OpenAI o1-1217 has a slight edge at 96.6%, while DeepSeek-R1 is right behind at 96.3%.
For SWE-bench Verified (software engineering reasoning), DeepSeek-R1 narrowly wins with 49.2% versus OpenAI o1-1217's 48.9%.
General knowledge
On GPQA Diamond (factual reasoning), OpenAI o1-1217 leads with 75.7% compared to DeepSeek-R1's 71.5%.
For MMLU (multitask language understanding), OpenAI o1-1217 edges ahead at 91.8% versus DeepSeek-R1's 90.8%.
The aftermath
DeepSeek-R1's launch has had some serious ripple effects:
Stock market impact
The release of an advanced, cheaper AI model hit U.S. tech stocks hard. Nvidia took an 18% nosedive, losing around $600 billion in market cap. Investors worried that efficient models like DeepSeek-R1 could reduce demand for Nvidia's expensive hardware.
AI economics & jevons' paradox
Open-weight models like DeepSeek-R1 are slashing costs and forcing AI companies to rethink pricing:
OpenAI's o1: $60 per million output tokens
DeepSeek-R1: $2.19 per million output tokens
Microsoft CEO Satya Nadella has hinted at Jevons' paradox – the idea that as efficiency increases, overall consumption rises rather than falls. His bet is that cheaper AI will explode demand.
But I think The Economist has a better take – a full Jevons effect is rare and depends on whether price is the main adoption barrier. With only "5% of American firms currently using AI and 7% planning to adopt it," many businesses still find AI integration challenging or unnecessary regardless of price.
The distillation controversy
OpenAI has accused DeepSeek of "distilling" their models – essentially claiming they extracted knowledge from OpenAI's systems and copied their performance into a smaller, more efficient package.
So far, OpenAI hasn't shown any real evidence for this claim. To many observers (myself included), it looks more like they're trying to reassure investors as the AI landscape shifts beneath their feet.
Conclusion
DeepSeek-R1 represents a game-changing moment in AI, delivering performance that rivals OpenAI's o1 at dramatically lower costs while maintaining an open-source approach. With its impressive benchmarks across mathematics, coding, and reasoning tasks, combined with pricing that's 96% cheaper than OpenAI's offerings, DeepSeek has fundamentally disrupted the AI landscape and forced a market-wide reevaluation of AI economics. The model's success proves that cutting-edge AI capabilities don't need to be locked behind expensive, closed systems, potentially accelerating widespread AI adoption and democratizing access to advanced reasoning technologies across industries worldwide.


